KUBERNETES 101: Architecture
PART II

Hey there! 👋 I'm Dev Jobalia, a Web Developer from India with a passion for Computer Science. I bring years of experience, a versatile tech toolkit, and a knack for fostering seamless teamwork.
#WebDev #TechEnthusiast #Teamwork
KUBECTL
kubectl is a command-line tool used to interact with and manage Kubernetes clusters. It is the primary command-line interface for working with Kubernetes and is often referred to as the "Kubernetes control plane." kubectl allows administrators, developers, and operators to perform various operations on a Kubernetes cluster, such as:
Deploying and Managing Applications
Cluster Configuration
Resource Inspection
Scaling
Updating Applications
Resource Deletion
Accessing Cluster Services
Kubernetes API Interaction
kubectl operates using a command-line interface (CLI), and it uses configuration files (usually stored in the ~/.kube directory) to determine which Kubernetes cluster it should interact with, as well as the user's authentication credentials.
Way Of Communication
Kubernetes provides two primary approaches for communicating with kubectl when working with resources: imperative and declarative. These approaches offer different ways to manage and interact with resources within a Kubernetes cluster.
Imperative Commands:
Imperative commands are action-oriented. You provide explicit instructions to
kubectlon what actions to take. For example:kubectl create deployment my-deployment --image=nginx kubectl expose deployment my-deployment --port=80 kubectl scale deployment my-deployment --replicas=3Imperative commands are useful when you want to perform one-off tasks or when you're more interested in specifying the exact steps to create and manage resources.
They can be concise and provide an easy way to perform tasks quickly, especially for ad-hoc or one-time operations.
Declarative Approach:
Declarative management involves specifying the desired state of your resources in a YAML or JSON file and then applying that configuration to the cluster. The Kubernetes controllers then work to reconcile the current state with the desired state.
# my-deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: my-deployment spec: replicas: 3 template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginxThe declarative approach is more infrastructure-as-code (IaC) friendly, and it makes it easier to manage configuration as code, store it in version control, and apply consistent changes to the cluster.
It promotes idempotency, meaning you can apply the same configuration multiple times, and it will only make changes if the actual state doesn't match the desired state.
You can use
kubectl applyto apply declarative configurations:kubectl apply -f my-deployment.yaml
In summary, imperative commands are suitable for ad-hoc operations and quick, explicit actions, while the declarative approach is well-suited for managing infrastructure and application configurations as code. When using the declarative approach, you define the desired state of resources, and Kubernetes takes care of reconciling the current state with the desired state, making it a more powerful and recommended approach for managing Kubernetes resources in production environments.
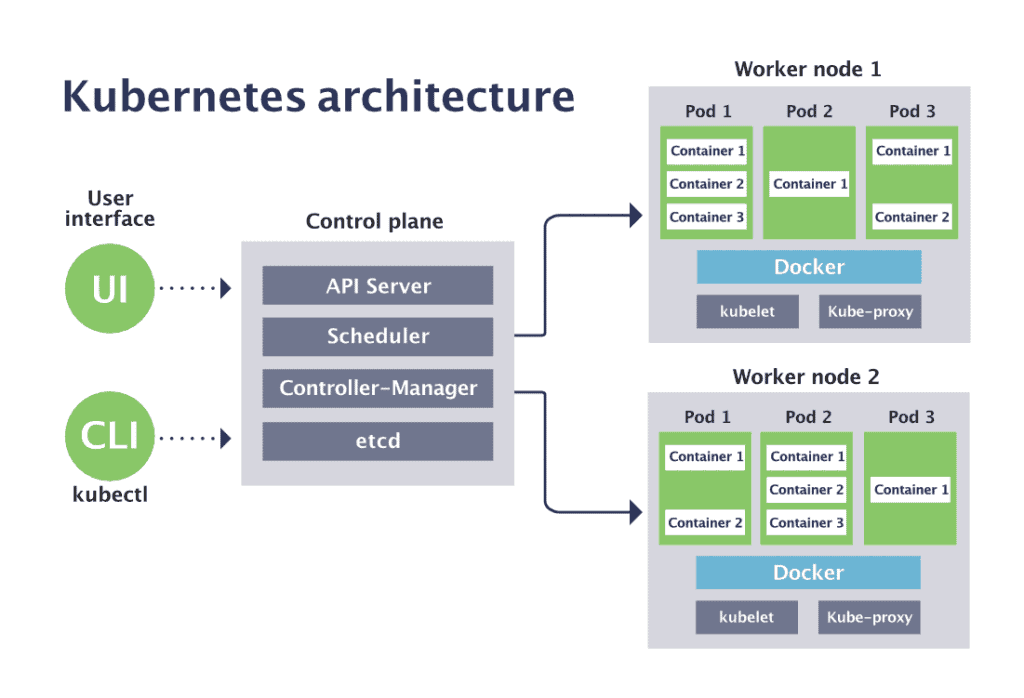
KUBERNETES CLUSTER
CLUSTER = CONTROL PLANE(MASTER NODE: NOT USED AS IT IS NOT INCLUSIVE NAMING CONVENTION) + NODES
A Kubernetes cluster is a set of physical or virtual machines (referred to as nodes) that are organized and managed collectively by Kubernetes. These nodes work together to run containerized applications and services. A Kubernetes cluster consists of several key components:
Control Plane (Master Node):
The master node is responsible for managing the overall state of the cluster. It coordinates and schedules tasks, manages the desired state of applications, and serves as the control plane for the cluster. The master node components include the Kubernetes API server, etcd (key-value store), controller manager, and scheduler.
It uses various components, including the Kubernetes API Server, Scheduler, and Controller Manager, to achieve these functions while controlling and maintaining the cluster's desired state.
Functions of the control plane:
Set Up a New Pod: When you create a new Pod, the control plane components, such as the Kubernetes API Server and the Scheduler, are responsible for managing the Pod's deployment and scheduling it to a suitable node in the cluster.
Create New Pods: Creating new Pods is a core function of the control plane. The control plane ensures that the desired number of Pods and their configurations are created and maintained.
Scale Pods: Scaling Pods, whether manually or automatically, is orchestrated by the control plane. This involves deploying additional Pods when scaling up and removing Pods when scaling down.
Destroy Something: Destroying or deleting Pods, as well as other Kubernetes resources, is managed by the control plane. When you issue a deletion request, the control plane ensures that the Pods are safely terminated.
Expose Something: Exposing a service is also managed by the control plane. Services provide stable endpoints for accessing Pods, and their configurations are controlled by the control plane.
Load Balancing: The control plane helps manage load balancing by directing network traffic to Pods and Services to ensure even resource utilization and high availability.
Resource Allocation: It allocates and manages resources (CPU, memory) for Pods and enforces resource constraints and limits.
Monitoring and Health Checks: The control plane continuously monitors the health and status of nodes, Pods, and applications. It performs health checks on Pods and nodes and takes action in case of failures.
Secrets and Configuration Management: The control plane is responsible for managing Secrets and ConfigMaps, which are used for securely storing sensitive data and application configuration.
Rolling Updates and Rollbacks: The control plane orchestrates rolling updates of applications and allows for easy rollbacks to a previous version in case of issues.
Authentication and Authorization: It enforces security measures like authentication and role-based access control (RBAC) to ensure that only authorized entities can perform certain actions within the cluster.
Pod Network Communication: It manages network policies to control communication between Pods, providing network segmentation and access control.
Event Logging and Auditing: The control plane logs events and actions, making it easier to troubleshoot and audit the cluster.
Resource Quotas and Limits: It enforces resource quotas and limits to ensure that applications do not consume more than their allocated resources.
Reconciliation Loops: Control plane components use reconciliation loops to compare the current state of resources with their desired state and take corrective actions as needed.
Custom Resource Definitions (CRDs): The control plane can be extended to manage custom resources and controllers using CRDs and Operators.

Components of Control Plane:
The control plane in Kubernetes is a collection of sub-components or services that work together to manage the cluster. These sub-components are responsible for various aspects of cluster management, including scheduling, API access, monitoring, and more. Here are some of the key sub-components of the control plane:
Kubernetes API Server (kube-apiserver):
This is the central component of the control plane.
It provides the Kubernetes API, which serves as the entry point for users, administrators, and other parts of the system to interact with the cluster.
The API server processes RESTful requests, validates them, and updates the corresponding objects in etcd, the cluster's key-value store.
Uses HTTP protocol at port 443
e.g. Send yaml file with pod definition to a server, for pod creation
etcd: Etcd is a distributed key-value store that acts as the cluster's database, storing all the configuration data and the current state of the cluster. It is a highly available, consistent, and reliable data store used by the control plane components.
Kubernetes Controller Manager (kube-controller-manager): This component hosts various controllers responsible for regulating the desired state of the system. Examples of controllers include the Replication Controller, Endpoint Controller, and Service Account & Token Controllers. These controllers continuously monitor the current state of resources and compare them to the desired state specified in Kubernetes objects. If discrepancies are identified, the controllers take action to make the necessary changes and ensure that the cluster's actual state aligns with the desired state.
Kubernetes Scheduler (kube-scheduler): The scheduler is responsible for placing objects or Pods on suitable nodes within the cluster. It takes into account factors like resource requirements, node health, networking requirements, and constraints to make placement decisions. The scheduler aims to optimize resource utilization and application performance. Importantly, the scheduler continuously listens to the API server to be informed about new Pods that need to be scheduled.
In Kubernetes, a scheduler is a critical component responsible for making decisions about which nodes (individual servers in a cluster) should run or host the various pods (the smallest deployable units) of your applications. The scheduler plays a central role in ensuring the efficient and effective allocation of resources in the cluster, balancing workloads, and maximizing resource utilization.
Here's how the Kubernetes scheduler works:
Pod Scheduling Request: When you create a new pod in Kubernetes or when pods are scaled up, rescheduled, or otherwise need to be placed on a node, a scheduling request is generated.
Node Selection: The scheduler evaluates available nodes in the cluster based on several factors, including the resource requirements and constraints of the pod, node capacity, and various policies.
Filtering and Scoring: The scheduler filters nodes that meet the pod's resource requirements and constraints, eliminating nodes that cannot accommodate the pod. It also assigns scores to the remaining nodes based on various factors such as resource availability, node health, and user-defined policies. The node with the highest score is the most suitable candidate for the pod.
Binding: After selecting the best node for the pod, the scheduler binds the pod to that node, ensuring that the pod runs on the chosen node.
Continuous Monitoring: The scheduler continues to monitor the cluster, and if a node becomes unsuitable for a pod due to node failure or resource constraints, the scheduler can reschedule the pod to a different node.
Kubernetes provides various mechanisms for influencing the scheduler's decision, including:
Node Affinity/Anti-Affinity: You can specify rules to indicate preferences or requirements for the pod to be scheduled on nodes with specific characteristics or labels.
Taints and Tolerations: Nodes can be "tainted" to repel pods unless the pods have corresponding "tolerations."
Resource Requests and Limits: Pods can specify resource requests and limits, which affect how nodes are selected based on resource availability.
Node Selectors: You can use node selectors to request that a pod be scheduled on nodes with specific labels.
Pod Priority and Preemption: You can assign priorities to pods, influencing the scheduler's decision on which pods to place when resources are constrained.
Custom scheduling policies can also be implemented by using custom schedulers or scheduler extensions.
In summary, the Kubernetes scheduler is a core component that automates the allocation and placement of pods on nodes in the cluster, ensuring efficient resource utilization and maintaining the desired state of applications in a Kubernetes environment.
Cloud Controller Manager: In cloud-based Kubernetes deployments, this component interacts with cloud provider APIs to manage resources such as virtual machines, load balancers, and storage volumes. Different cloud providers may have their own controller managers.
Cluster DNS: This component provides DNS-based service discovery within the cluster. It enables Pods to discover and communicate with other services using DNS names.
API Aggregation Layer: This layer allows custom API servers to be served alongside the primary Kubernetes API server. It is useful for extending the API with custom resources and controllers.
Admission Controllers: Admission controllers are responsible for intercepting requests to the API server and ensuring that they meet certain criteria before they are accepted. Examples include the PodSecurityPolicy controller, which enforces security policies, and the ValidatingAdmissionWebhook, which can be used for custom validation.
API Server Proxies: In larger clusters, you can deploy API server proxies to help load balance traffic to the API server and provide some degree of fault tolerance.
These sub-components work in harmony to manage the cluster's configuration and ensure the desired state of resources is maintained. They collectively provide the control plane's functionality, enabling you to interact with and operate Kubernetes clusters effectively.
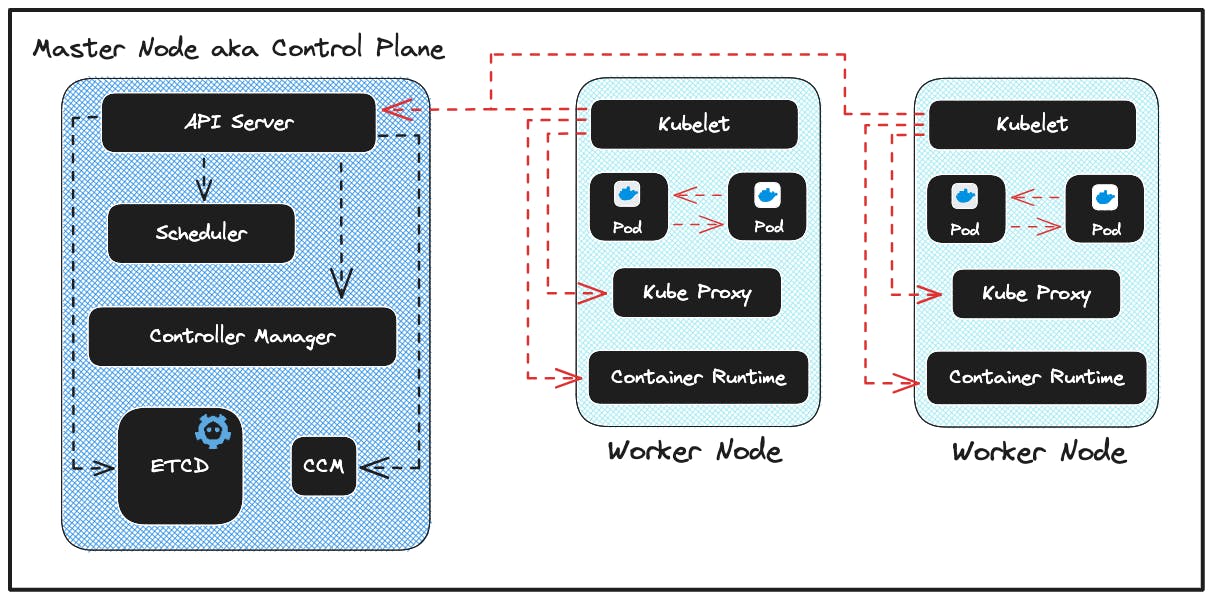
Worker Nodes (Minions):
Worker nodes, also known as minions, are the machines where containers are deployed and run. These nodes are responsible for executing the tasks assigned by the master node. Each worker node runs a container runtime (e.g., Docker, containerd) and the Kubernetes Node Agent (kubelet) to manage containers. Worker nodes can be scaled to accommodate more containers and applications. here is where your application will run.
Sub-component of Worker nodes:
Kubelet: The kubelet is a crucial component running on each worker node. It communicates with the master node and ensures that containers are running in the pods as specified in the desired state.
Pods: Pods are the smallest deployable units in Kubernetes. They can contain one or more containers, which share the same network and storage space within the pod. Containers within a pod are co-located and tightly coupled.
A Pod is indeed the smallest deployable unit in Kubernetes. It's the basic building block for running containerized applications.
It's a higher-level abstraction that can encapsulate one or more containers. Containers within a Pod share the same network namespace, meaning they can communicate with each other using
localhost, and they can also share the same storage volumes.While containers are often used within Pods, Kubernetes itself is container runtime-agnostic. You can run Pods with containers based on different container runtimes, such as Docker, containerd, or CRI-O, depending on your cluster's configuration.
In summary, a Pod in Kubernetes is a lightweight, logical host that can run one or more containers, sharing network and storage resources. It provides a level of isolation and encapsulation for co-located containers while allowing them to work together in a single scheduling unit.
Best Practice: one container in one pod
Kube Proxy: Kube Proxy is responsible for network communication to and from services and pods in a Kubernetes cluster. It maintains network rules on worker nodes to enable network routing to the correct pods and services, ensuring that traffic is correctly directed. IP addresses for nodes are typically assigned and managed separately by the underlying infrastructure, such as a cloud provider or network configuration.
Container Runtime: In Kubernetes, a container runtime is the software responsible for running containers. It is the component that manages and executes the containers, handling tasks like starting, stopping, and interacting with container images. Common container runtimes used in Kubernetes include Docker, containerd, and CRI-O.
docker without cri: the old version was not compatible
docker with cri: is supported on k8s
the industry was moving towards container runtimes like containerd and CRI-O, primarily because they are designed with Kubernetes in mind and offer a more streamlined container runtime experience.
Add-Ons and Extensions:
Kubernetes clusters can be extended with various add-ons and extensions, such as a container network interface (CNI) plugin, Ingress controllers, and monitoring solutions.
A Kubernetes cluster is designed for high availability and can be scaled horizontally to accommodate more nodes as needed. Clusters can be deployed on on-premises hardware, cloud providers (e.g., AWS, Google Cloud, Azure), or in hybrid cloud environments. Managing a Kubernetes cluster efficiently requires considering factors like security, resource allocation, and monitoring to ensure that containerized applications run smoothly and reliably.
kubernetes objects
In Kubernetes, objects are the fundamental building blocks used to define the desired state of the cluster. Kubernetes objects represent the various resources and entities that make up your applications, services, and the overall cluster configuration. These objects are defined using YAML or JSON configuration files and are submitted to the Kubernetes API server for creation and management. Here are some common Kubernetes objects:
Pod:
The smallest deployable unit in Kubernetes.
A pod can contain one or more containers that share the same network and storage space.
Deployment:
Manages the creation and scaling of pods.
Enables rolling updates and rollbacks for application versions.
Service:
Defines a logical set of pods and a policy for accessing them.
Provides load balancing and service discovery for pods.
A Kubernetes service provides a stable, load-balanced endpoint for accessing a set of pods. It abstracts the details of the underlying pod IP addresses and allows applications to communicate with services without needing to know which specific pod is serving the request.
ReplicaSet:
Ensures that a specified number of pod replicas are running at all times.
Used for scaling and maintaining a desired number of pods.
StatefulSet:
- Manages stateful applications, such as databases, by providing stable network identities and ordered deployment and scaling.
DaemonSet:
Ensures that a pod runs on all (or a subset of) nodes in a cluster.
Often used for cluster-level services like logging and monitoring agents.
ConfigMap and Secret:
Store configuration data and secrets as key-value pairs.
These objects are mounted as volumes in pods to provide configuration data.
Namespace:
Provides a way to logically divide a single Kubernetes cluster into multiple virtual clusters.
Used for resource and access control.
Kubernetes namespaces are used to logically isolate and segment different applications and resources within the same cluster. They provide a way to organize and manage resources, allowing multiple teams or applications to coexist within the same cluster.
ServiceAccount:
Defines the identity of pods running in the cluster.
Used for managing access and permissions.
PersistentVolume (PV) and PersistentVolumeClaim (PVC):
PV represents a physical storage resource in the cluster.
PVC is a request for storage by a user or application.
PVCs claim PVs for storage needs.
Ingress:
Manages external access to services in the cluster.
Provides HTTP and HTTPS routing rules for directing traffic.
HorizontalPodAutoscaler (HPA):
- Automatically scales the number of pods in a deployment or replica set based on resource utilization or custom metrics.
Job and CronJob:
Job runs a task to completion, ensuring that it is completed successfully.
CronJob schedules a job to run at specified intervals.
NetworkPolicy:
Defines how groups of pods are allowed to communicate with each other.
Provides network segmentation and isolation.
Role and RoleBinding, ClusterRole and ClusterRoleBinding:
- Manage access control to Kubernetes resources by defining permissions and linking them to users or service accounts.
Kubernetes objects are used to declare the desired state of your applications and the way they should interact with the cluster's infrastructure. The Kubernetes control plane then works to ensure that the actual state matches the desired state defined in these objects.
CONTROLLER
In Kubernetes, controllers are control loops that watch the state of your cluster, and then make or request changes where needed. Each controller tries to move the current cluster state closer to the desired state of resources, such as Pods.
Types of built-in controller
Kubernetes offers various types of controllers to manage different aspects of resource lifecycles in a cluster. Here are some common types of controllers in Kubernetes:
Deployment:
Manages application deployments and scaling, ensuring that a specified number of replicas are running.
Supports rolling updates and rollbacks for version changes.
ReplicaSet:
Ensures a specified number of replica Pods are running at all times.
Often used in conjunction with Deployments to maintain a stable set of replicas.
StatefulSet:
Manages stateful applications, such as databases, by providing stable network identities, ordered deployment, and scaling capabilities.
Ensures that Pods maintain unique identities.
DaemonSet:
Ensures that a Pod runs on all or a subset of nodes in a cluster.
Often used for cluster-level services like logging and monitoring agents.
Job:
Runs a task to completion and ensures that it succeeds.
Suitable for batch processing and one-time job execution.
CronJob:
Schedules Jobs to run at specified intervals, like cron tasks.
Useful for recurring or scheduled tasks.
HorizontalPodAutoscaler (HPA):
- Automatically scales the number of Pods in a Deployment, ReplicaSet, or StatefulSet based on resource utilization or custom metrics.
Namespace:
Provides a way to logically divide a single Kubernetes cluster into multiple virtual clusters.
Used for resource and access control, especially in multi-tenant environments.
Service:
Manages a set of Pods and provides a stable endpoint for accessing them.
Supports load balancing and service discovery.
Ingress:
Manages external access to services in the cluster.
Defines routing rules for directing incoming traffic to services.
NetworkPolicy:
Defines how groups of Pods are allowed to communicate with each other.
Provides network segmentation and access control.
CustomResourceDefinition (CRD):
- Allows you to define custom resource types and controllers that can extend Kubernetes' capabilities to handle domain-specific resources.
Controller for Custom Resources:
- You can create custom controllers for custom resources using Operators to automate and manage domain-specific resources.
ServiceAccount:
Defines the identity for Pods running in the cluster.
Used for managing access and permissions.
PodDisruptionBudget:
- Defines the minimum number of Pods that must be available during disruptions like node maintenance.
ClusterRole and ClusterRoleBinding:
- Manage access control for cluster-wide resources.
These controllers play a critical role in managing different aspects of application deployment, scaling, and maintenance within a Kubernetes cluster. Each controller type serves specific use cases and helps ensure the desired state of resources while abstracting many of the operational complexities associated with managing distributed applications.
K8S DNS
each ip address assigned to pod helps in internal communication with pods
it is based of core dns
In a Kubernetes cluster, DNS (Domain Name System) is an essential component responsible for providing service discovery and name resolution for various resources within the cluster. The primary functions of DNS in Kubernetes include:
Service Discovery: Kubernetes DNS allows Pods and services to discover and communicate with each other using human-readable domain names. Each Kubernetes Service is assigned a DNS name that can be used by other services or Pods to access it.
DNS Names for Services: When you create a Kubernetes Service, a DNS entry is automatically generated for it. The DNS name follows the pattern
<service-name>.<namespace>.svc.cluster.local, where:<service-name>is the name of the Kubernetes Service.<namespace>is the namespace where the Service is deployed.svc.cluster.localis the default DNS domain for services.
Pod-to-Pod Communication: Pods can use the DNS names of other Pods or services to communicate with them, making it easier to establish connections between different components within the cluster.
Headless Services: Kubernetes allows you to create "headless" services, where each Pod in a Service is assigned its DNS A or AAAA record. This enables direct DNS-based communication between Pods without load balancing.
Cluster DNS Resolution: Cluster DNS is available by default to all Pods in a Kubernetes cluster. Pods can use DNS to resolve the names of other services, endpoints, or external resources.
Custom DNS Policies: Kubernetes allows you to configure custom DNS policies for Pods, including custom DNS servers and search domains.
Service Endpoints: The DNS system is aware of the endpoints for a Service. When you query the DNS name of a Service, it returns the IP addresses of the Pods behind that Service.
Load Balancing: DNS load balancing is automatically performed by Kubernetes for services with multiple endpoints. When a Pod queries the DNS name of a Service, it receives one of the available endpoint IP addresses, distributing the load among the Pods.
CoreDNS: In modern Kubernetes clusters, CoreDNS is often used as the DNS server to provide these capabilities. CoreDNS is a flexible, extensible DNS server that can be configured to support various DNS policies.
By using DNS, Kubernetes simplifies the process of service discovery and communication within the cluster, allowing developers and operators to use human-readable names rather than dealing with IP addresses and manual configuration. DNS is a fundamental component for building and managing containerized applications in a Kubernetes environment.
General workflow for deploying applications as microservices in a Kubernetes cluster:
1. Create Microservices:
- Divide your application into smaller, more manageable components, often referred to as microservices. Each microservice should perform a specific function within your application. This step involves designing and developing these microservices.
2. Containerize Microservices:
- Once your microservices are developed, containerize each one separately. Containerization involves packaging the microservices and their dependencies into containers using technologies like Docker. Each microservice should have its own container.
3. Put Containers in Pods:
- In Kubernetes, you place individual containers within Pods. A Pod can contain one or more containers that share the same network namespace and storage volumes. The primary purpose of Pods is to provide a scheduling and co-location unit for containers. However, it's essential to note that it's common practice to place a single container per Pod, especially when using microservices to promote isolation and scalability.
4. Deploy Pods to Controllers:
- Kubernetes offers controllers like Deployments, ReplicaSets, and StatefulSets, which help manage the lifecycle of Pods. These controllers are responsible for ensuring that the desired number of Pods are running, handling scaling, rolling updates, and maintaining the desired state of your microservices.
To expand on your analogy, you can think of Pods as the basic building blocks (primitive data types) for deploying containers, and Deployment a type of controllers as higher-level data structures (complex data types) that manage the scaling and overall lifecycle of your Pods. This approach allows you to independently scale and manage each microservice while leveraging Kubernetes for orchestration, scaling, and management of the application components.
K8S DEPLOYMENT
In Kubernetes, a "Deployment" is a resource object that provides declarative updates to applications. It allows you to describe the desired state of an application, including the number of desired replica Pods and the application's template. Deployments are commonly used to manage the lifecycle of application Pods and ensure high availability, scalability, and rolling updates.
Here are some key features and components of Deployments in Kubernetes:
Desired State Specification
Replica Sets
Rolling Updates
Scalability
Rollbacks
Declarative Configuration
Immutable Updates
Here's an example of a simple Deployment manifest:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app-deployment
spec:
replicas: 3
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-app-container
image: my-app:v2
In this example, the Deployment specifies that it should maintain three replicas of the "my-app-container." If you want to update the application to a new version (e.g., v3), you would update the image in the Deployment manifest, and the Deployment controller will manage the rolling update for you.
Deployments are a fundamental building block for managing containerized applications in Kubernetes, providing ease of management, scalability, and robust updates.
Note: YAML file also called kubernetes manifest files.
REFERENCES


